6月14-19日,2020年国际计算机视觉与模式识别学术会议(IEEE/CVF Conference on Computer Vision and Pattern Recognition,CVPR)首次采用线上形式成功举行。作为世界顶级的计算机视觉领域学术会议,2020 CVPR大会号称十年来最难的一届,论文录用率仅为 22%,为十年来最低。澳门太阳在本届大会收获颇丰,共有6篇论文入选,其中1篇获选大会Oral论文,同时在大会竞赛中斩获2项冠军。
硕士研究生綦浩喆、冯晨等在曹治国教授、肖阳副教授指导下的研究成果“P2B:Point-to-Box Network for 3D Object Tracking in Point Clouds”被选为大会Oral论文。该论文着眼于在点云中进行3D目标跟踪,其创新点在于提出了一种新型的端到端的由点到盒的网络(P2B,Point to Box),它以点为核心基元,从模板点云和搜索区域点云中分别采集种子点,通过一种置换不变的手段将模板中的目标信息嵌入到搜索区域,使得搜索种子点都拥有目标特定特征,再通过霍夫投票回归潜在的目标中心,进行由点驱动的一体化的3D目标候选框的查找和验证。论文方法在KITTI跟踪数据集上取得了当前最好的效果,并可以在单个NVIDIA 1080Ti GPU上以40FPS的速度运行。

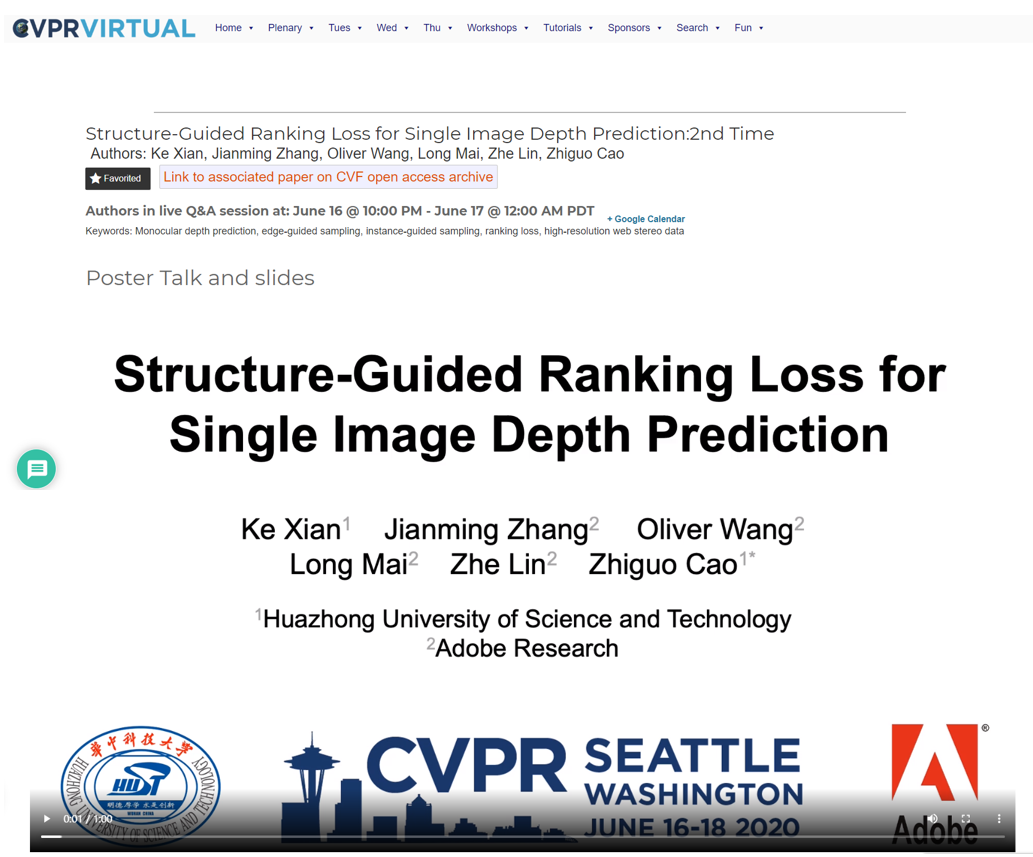
博士研究生鲜可在导师曹治国教授,以及Adobe Research公司的Jianming Zhang博士、Oliver Wang博士、Long Mai博士、Zhe Lin博士的共同指导下,在大会发表论文“Structure-guided Ranking Loss for Single Image Depth Prediction”。该论文的研究工作得到国家自然科学基金面上项目和Adobe Gift的资助,针对现有单张图像深度估计模型无法预测出物体一致性好、边缘准确的深度图,提出了一种结构化引导的排序损失函数,结合底层边缘引导和高层实例引导的在线采样,来引导模型专注于深度重建中最难、最重要的部分--深度不连续性。同时,为了提升模型的泛化性能,提出了一个新的高分辨率的相对深度数据集。作者在六个公开的深度数据集上进行了测试,测试结果表明论文提出的模型具有最优的泛化性能,达到了目前业界最佳效果。
硕士研究生王焱乘在肖阳副教授、曹治国教授指导下,与美国纽约州立大学布法罗分校的袁浚崧教授和新加坡高科技研究局A*STAR的周天异研究员合作,发表了“3DV:3D Dynamic Voxel for Action Recognition in Depth Video”论文。该论文提出了一种新的三维动态体素(3DV)表示方法,来进行3D人体行为识别。其核心思想是通过时序池化将深度视频中的三维运动信息压缩成规则体素集(即3DV),再以端到端的学习方式将点集送入到PointNet++中进行3D动作识别。针对3DV可能丢失外观细节信息的问题,提出了一种多流的3D动作识别方法,将运动特征和外观特征结合起来共同学习。论文在4个已建立的基准数据集上的实验证明了该方法的优越性。

博士研究生余昌黔在桑农教授、高常鑫副教授和澳大利亚阿德莱德大学的沈春华教授的指导下,在大会发表了“Context Prior for Scene Segmentation”论文。该论文的研究工作在国家自然科学基金重点项目的资助下,针对场景分割问题,提出了一种上下文先验用于显式聚合类内上下文和类间上下文信息。当前的分割模型主要基于金字塔方法和注意力方法聚合上下文信息增强模型表征能力,然而这些方法不能区分不同类型的上下文信息,混合的信息对模型的学习过程产生了负面影响。因此本研究提出了上下文先验,通过设计理想的相似性矩阵和先验损失函数,优化监督需要学习的上下文先验图,从而显式聚合类内上下文信息和类间上下文信息,为场景分割提供了更明确的上下文信息。实验结果表明,该方法在多个常用语义分割数据集上性能超越其他方法,达到目前的最佳性能。

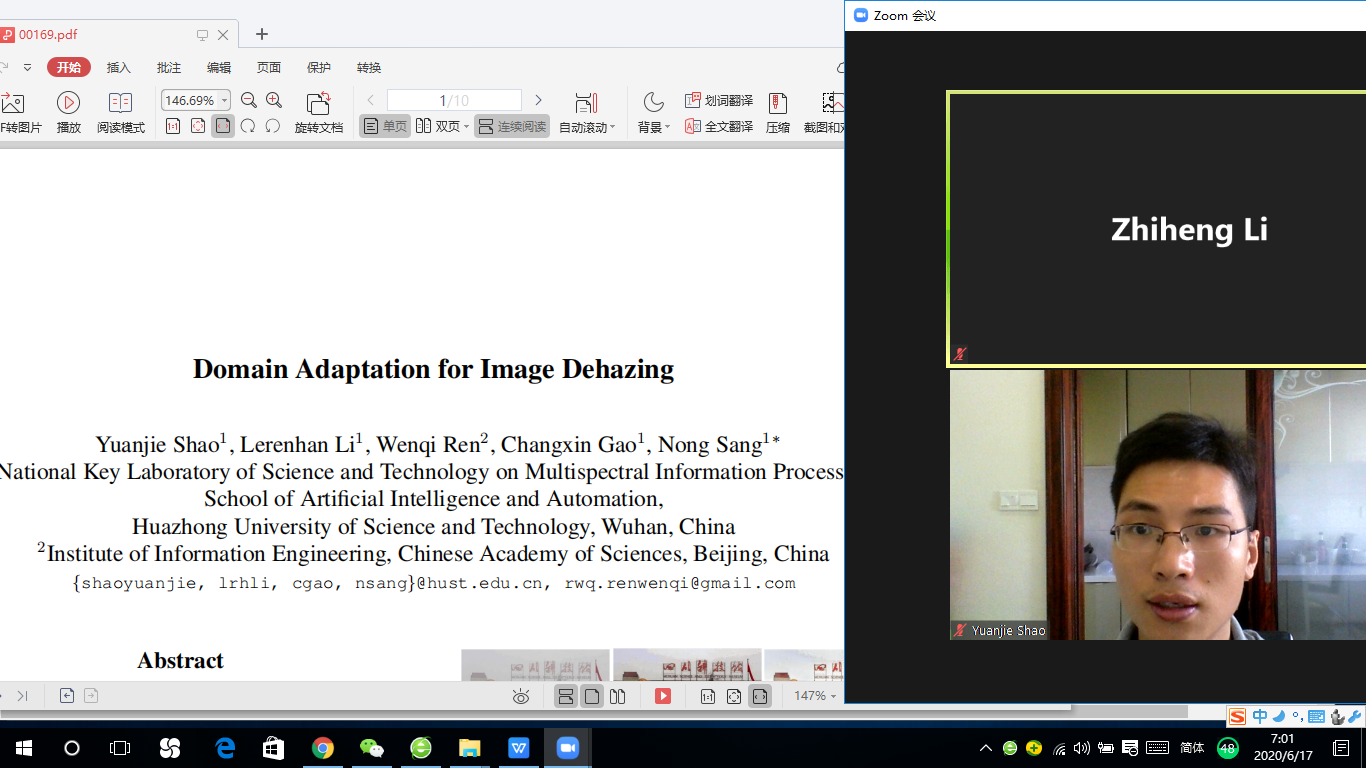
博士后邵远杰、博士生李乐仁瀚等同学在桑农教授、高常鑫副教授指导下,发表了“Domain Adaptation for Image Dehazing”论文,该论文的研究工作在国家自然科学基金重点项目的资助下,针对传统的图像去雾模型仅在合成雾天图像上训练,在真实雾天图像上泛化性不足的问题,提出一种基于域自适应的图像去雾框架,它包含一个图像转换模块和两个图像去雾模块。首先,利用一个双边转换网络将一个领域的图像转换到另一个领域,从而减小合成域和真实域之间的差异。然后,再利用转换前和转换后的图像来训练两个图像去雾网络,并通过一致性损失将这两个网络联系起来。在这个训练阶段,通过挖掘清晰图像的属性(如暗通道先验和图像梯度平滑)来将真实雾天图像也加入到去雾网络的训练中,从而进一步提升网络的域适应性。通过端到端的训练图像转换和去雾网络,在图像转换和去雾方面都可以获得更好的效果。在合成和真实数据集上的实验结果也表明我们的算法的优越性。
硕士生密振兴和罗一鸣同学在陶文兵教授指导下以共同第一作者在CVPR2020发表论文一篇,论文“Zhenxing Mi#, Yiming Luo#, Wenbing Tao*, SSRNet: Scalable 3D Surface Reconstruction Network. CVPR2020” 首次解决了采用深度学习进行大规模点云(千万级以上)的表面重建问题,在表面重建性能、效率和可扩展性方面均优于现有的几何的或是基于学习的表面重建算法,且算法具有较好的泛化性能,在少数几个点云数据上进行训练后便可广泛应用到各种大规模点云数据的表面重建。

在大会竞赛中,澳门太阳桑农教授、高常鑫副教授指导硕士生卿志武、马百腾,以及本科生王翔等参加了大会组织的国际大规模动作识别ActivityNet竞赛,并夺得ActivityNet时序行为定位(Temporal Action Localization (ActivityNet))和HACS有监督时序行为定位(HACS Temporal Action Localization Challenge 2020:Supervised Learning Track)两个赛道的冠军。
时序行为定位是目前视频理解方向的研究热点。国际大规模动作识别竞赛ActivityNet是视频动作识别与时序行为检测领域的重要竞赛。作为视频理解的基础技术之一,时序行为检测具有广泛的应用前景,相关技术在智能生产、视频智能剪辑、智能监控、视频内容检索、视频分析、活体检测等多项实际应用中具有重要价值。在ActivityNet时序行为定位比赛中,团队提出了一种名为CBR-Net的深度学习网络。CBR-Net网络融合了视频中的时序依赖信息,并同时对得到的定位结果进行微调,产生边界精度更高的定位结果。最终,凭借CBR-Net网络,以42.788mAP夺得冠军。
HACS(Human Action Clips and Segments)是2019年由麻省理工学院(MIT)提出的用于行为识别和时序行为检测的大规模数据集。该数据集不仅包含的视频数量远超之前的所有的时序行为检测数据集,而且单个视频的时序行为标注更加复杂,更加接近现实应用。在HACS有监督时序行为定位比赛中,团队提出了更加高效的视频级别分类方法,利用多模型的互补性极大提高了分类性能。在时序提议生成中,针对现有方法中在HACS数据集的不足,提出融合时序上的高阶特征的方法,有效提高了时序提议的质量。最终在测试集上mAP达到40.53%夺得冠军,比第二名39.33%高出1.2%mAP。


 学院公众号二维码
学院公众号二维码